Concurrent programming in Java with virtual threads
Introduction
Java virtual threads are lightweight threads designed to increase throughput in concurrent applications. Pre-existing Java threads were based on operating system (OS) threads that proved insufficient to meet the demands of modern concurrency. Servers nowadays must serve millions of concurrent requests, but the OS and thus the JVM cannot efficiently handle more than a few thousand threads.
Currently, programmers can either use threads as the units of concurrency and write synchronous blocking code in the thread-per-request model. These applications are easier to develop, but they are not scalable because the number of OS threads is limited. Or, programmers can use other asynchronous/reactive models that reuse threads without blocking them. Such applications, while having much better scalability, are much more difficult to implement, debug, and understand.
Virtual threads developed inside Project Loom can solve this dilemma. New virtual threads managed by the JVM, can be used alongside the existing platform threads managed by the OS. Virtual threads are much more lightweight than kernel threads in memory usage, and their blocking and context-switching overhead is negligible. Programmers can create millions of virtual threads and achieve similar scalability using much simpler synchronous blocking code.
All information in this article corresponds to OpenJDK 21.
Why virtual threads?
Concurrency and parallelism
Before telling what virtual threads are, we need to explain how they can increase the throughput of concurrent applications. To begin with, it is worth explaining what concurrency is and how it differs from parallelism.
Parallelism is a technique to accelerate a single task by internally splitting it into cooperating subtasks scheduled on multiple computing resources. In parallel applications, we are most interested in latency (duration of task processing in time units). An example of parallel applications is specialized image processors.
Concurrency, in contrast, is a technique to schedule multiple concurrent tasks that come from outside on multiple computing resources. In concurrent applications, we are most interested in throughput (number of tasks processed per time unit). An example of concurrent applications is servers.
Little’s Law
In mathematical theory, Little’s Law is a theorem that describes the behavior of concurrent systems. A system means some arbitrary boundary in which tasks (customers, transactions, or requests) arrive, spend time inside and then leave. The theorem applies to a stable system, where tasks enter and leave at the same rate (rather than accumulating in an unbounded queue). Also, tasks should not be interrupted and not interfere with each other. (All the variables in the theorem refer to long-term averages in an arbitrary period, within which probabilistic variations are irrelevant).
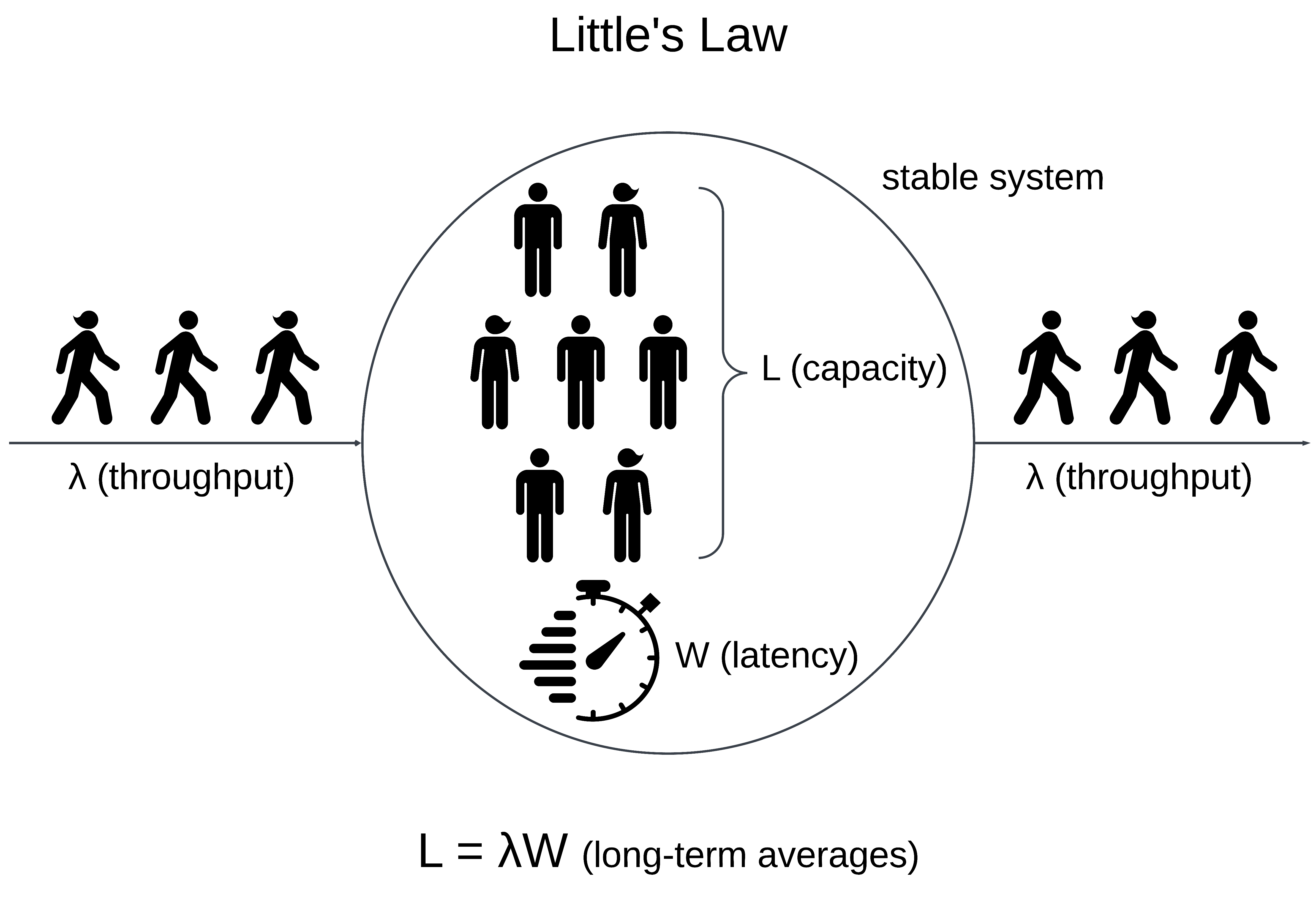
The theorem states that the number L of tasks being concurrently handled (capacity) in such a system is equal to the arrival rate λ (throughput) multiplied by the time W that a task spends in the system (latency):
L = λW
Since Little’s Law applies to any system with arbitrary boundaries, it applies to any subsystem of that system.
Servers are concurrent systems
Little’s Law applies to servers as well. A server is a concurrent system that processes requests and contains several subsystems (CPU, memory, disc, network). The duration of each request depends on how the server processes it. Programmers can try to reduce the duration, but eventually, they come to a limit. In well-designed servers, requests do not interfere with each other, and so latency depends little on the number of simultaneous requests. The latency of each request depends on the inherited properties of the server and can be considered constant. Thus, the throughput of a server is primarily a function of its capacity.
In most servers, requests execute I/O-bound tasks. These servers often have problems with the utilization of the CPU subsystem. This happens when the OS can no longer support more active threads, but the CPU is not used at 100%. When we move to the CPU subsystem, we also move from requests to threads as units of concurrency. (We will consider servers designed on the thread-per-request model).
Threads in such requests use the CPU for a short time and spend most of the time waiting for blocking OS operations to complete. When a waiting thread is blocked, the scheduler can switch the CPU core to execute another thread. Simplified, if a thread uses the CPU for only 1/N of its execution time, then a single CPU core can handle N threads simultaneously.
For example, a CPU has 24 cores and the total request latency is W=100 ms. If a request spends WCPU=10 ms, then to fully utilize the CPU you need to have 240 threads. If a request requires much less computing resources and spends WCPU=0.1 ms, then to fully utilize the CPU you already need to have 24000 threads. However, a mainstream OS cannot support that number of active threads, mainly because their stack is too large. (A consumer-grade computer nowadays rarely supports more than 5000 active threads). Therefore, server computational resources are often underutilized when executing I/O bounded requests.
User-mode threads are the solution
The solution that the Loom Project team has chosen is to implement user-mode threads similar to those used in Go. These lightweight threads were named virtual threads by analogy to virtual memory. This name suggests that virtual threads are numerous and cheap thread-like entities that efficiently utilize computational resources. Virtual threads are implemented by the JVM (instead of the OS kernel), which manages their stack at a lower granularity than the OS can. So instead of a few thousand threads at best, programmers can have millions of threads in a single process. This solution provides an excellent concurrent capacity because this is what Little’s Law requires to achieve high throughput.
Platform threads and virtual threads
For the OS, threads are independent execution units that belong to a process. Each thread has an execution instruction counter and a call stack but shares a heap with other threads in the same process. For the JVM, threads are instances of the Thread class, which is a thin wrapper for OS threads. There are two kinds of threads: platform threads and virtual threads.
Platform threads
Platform threads are kernel-mode threads mapped one-to-one to kernel-mode OS threads. The OS schedules OS threads and hence, platform threads. The OS affects the thread creation time and the context switching time, as well as the number of platform threads. Platform threads usually have a large, fixed-size stack allocated in a process stack segment with page granularity. (For the JVM running on Linux x64 the default stack size is 1 MB, so 1000 OS threads require 1 GB of stack memory). So, the number of available platform threads is limited to the number of OS threads.
Platform threads are suitable for executing all types of tasks, but their use in long-blocking operations is a waste of a limited resource.
Virtual threads
Virtual threads are user-mode threads mapped many-to-many to kernel-mode OS threads. Virtual threads are scheduled by the JVM, rather than the OS. A virtual thread is a regular Java object, so the thread creation time and context switching time are negligible. The stack of virtual threads is much smaller than for platform threads and is dynamically sized. (When a virtual thread is inactive, its stack is stored in the JVM heap). Thus, the number of virtual threads does not depend on the limitations of the OS.
Virtual threads are suitable for executing tasks that spend most of the time blocked and are not intended for long-running CPU-intensive operations.
A summary of the quantitative differences between platform and virtual streams:
| Parameter | Platform threads | Virtual threads |
| stack size | 1 MB | resizable |
| startup time | > 1000 µs | 1-10 µs |
| context switching time | 1-10 µs | ~ 0.2 µs |
| number | < 5000 | millions |
The implementation of virtual threads consists of two parts: continuation and scheduler.
Continuations are a sequential code that can suspend itself and later be resumed. When a continuation suspends, it saves its content and passes control outside. When a continuation is resumed, control returns to the last suspending point with the previous context.
By default, virtual threads use a work-stealing ForkJoinPool scheduler. Their scheduler is pluggable, and any other scheduler that implements the Executor interface can be used instead. The schedulers do not even need to know that they are scheduling continuations. From their view, they are ordinary tasks that implement the Runnable interface. The scheduler executes virtual threads on a pool of several platform threads used as carrier threads. By default, their initial number is equal to the number of available CPU cores, and their maximum number is 256.
Running an application with system property -Djdk.defaultScheduler.parallelism=N changes the number of carrier threads.
When a virtual thread calls a blocking I/O method, the scheduler performs the following actions:
- unmounts the virtual thread from the carrier thread
- suspends the continuation and saves its content
- start a non-blocking I/O operation in the OS kernel
- the scheduler can execute another virtual thread on the same carrier thread
When the I/O operation completes in the OS kernel, the scheduler performs the opposite actions:
- restores the content of the continuation and resumes it
- waits until a carrier thread is available
- mounts the virtual thread to the carrier thread
To provide this behavior, most of the blocking operations in the Java standard library (mainly I/O and synchronization constructs from the java.util.concurrent package) have been refactored. However, some operations do not yet support this feature and capture the carrier thread instead. This behavior can be caused by current limitations of the OS or of the JDK. The capture of an OS thread is compensated by temporarily adding a carrier thread to the scheduler.
A virtual thread also cannot be unmounted during some blocking operations when it is pinned to its carrier. This occurs when a virtual thread executes a synchronized block/method, a native method, or a foreign function. During pinning, the scheduler does not create an additional carrier thread, so frequent and long pinning may degrade scalability.
How to use virtual threads
Virtual threads are instances of the nonpublic VirtualThread class, which is a subclass of the Thread class.
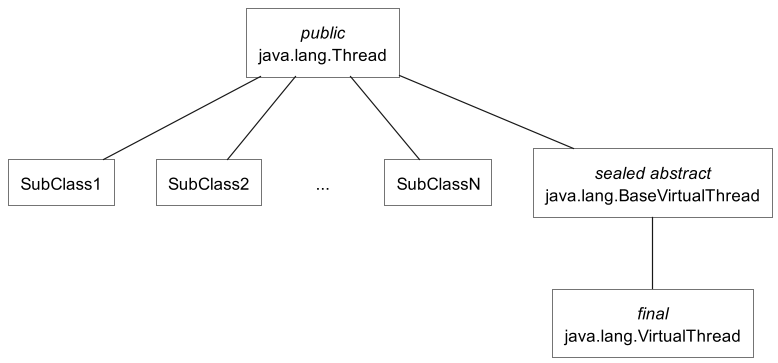
The Thread class has public constructors and the inner Thread.Builder interface for creating and starting threads. For backward compatibility, all public constructors of the Thread class can create only platform threads for now. Virtual threads are instances of a class that does not have public constructors, so the only way to create virtual threads is to use a builder. (A similar builder exists for creating platform threads).
The Thread class has new methods to handle virtual threads:
| Modifier and type | Method | Description |
| final boolean | isVirtual() | Returns true if this thread is a virtual thread. |
| static Thread.Builder.OfVirtual | ofVirtual() | Returns a builder for creating a virtual Thread or ThreadFactory that creates virtual threads. |
| static Thread | startVirtualThread(Runnable) | Creates a virtual thread to execute a task and schedules it to execute. |
There are four ways to use virtual threads:
- the thread builder
- the static factory method
- the thread factory
- the executor service
The virtual thread builder allows you to create a virtual thread with all available parameters: name, inheritable-thread-local variables inheritance flag, uncaught exception handler, and Runnable task. (Note that the virtual threads are daemon threads and have a fixed priority that cannot be changed).
Thread.Builder builder = Thread.ofVirtual()
.name("virtual thread")
.inheritInheritableThreadLocals(false)
.uncaughtExceptionHandler((t, e) -> System.out.printf("thread %s failed with exception %s", t, e));
assertEquals("java.lang.ThreadBuilders$VirtualThreadBuilder", builder.getClass().getName());
Thread thread = builder.unstarted(() -> System.out.println("run"));
assertEquals("java.lang.VirtualThread", thread.getClass().getName());
assertEquals("virtual thread", thread.getName());
assertTrue(thread.isDaemon());
assertEquals(5, thread.getPriority());
In the platform thread builder, you can specify additional parameters: thread group, daemon flag, priority, and stack size.
The static factory method allows you to create a virtual thread with default parameters, by specifying only a Runnable task. (Note that by default, the virtual thread name is empty).
Thread thread = Thread.ofVirtual().start(() -> System.out.println("run"));
thread.join();
assertEquals("java.lang.VirtualThread", thread.getClass().getName());
assertTrue(thread.isVirtual());
assertEquals("", thread.getName());
The thread factory allows you to create a virtual thread by specifying a Runnable task to the ThreadFactory.newThread(Runnable) method. The parameters of virtual threads are specified by the current state of the thread builder from which this thread factory is created. (Note that the thread factory is thread-safe, but the thread builder is not).
Thread.Builder builder = Thread.ofVirtual()
.name("virtual thread");
ThreadFactory factory = builder.factory();
assertEquals("java.lang.ThreadBuilders$VirtualThreadFactory", factory.getClass().getName());
Thread thread = factory.newThread(() -> System.out.println("run"));
assertEquals("java.lang.VirtualThread", thread.getClass().getName());
assertTrue(thread.isVirtual());
assertEquals("virtual thread", thread.getName());
assertEquals(Thread.State.NEW, thread.getState());
The executor service allows you to execute Runnable and Callable tasks in the unbounded, thread-per-task instance of the ExecutorService interface.
try (ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor()) {
assertEquals("java.util.concurrent.ThreadPerTaskExecutor", executorService.getClass().getName());
Future<?> future = executorService.submit(() -> System.out.println("run"));
future.get();
}
How to properly use virtual threads
The Project Loom team had a choice whether to make the virtual thread class a sibling class or a subclass of the existing Thread class. They have chosen the second option, and now existing code can use virtual threads with little or no changes. However, as a result of this trade-off, some features that were widely used for platform threads are useless or even harmful for virtual threads. The responsibility for knowing and avoiding known pitfalls is now on the programmer.
Do not use virtual threads for CPU-bound tasks
The OS scheduler for platform threads is preemptive*. The OS scheduler uses time slices to suspend and resume platform threads. Thus, multiple platform threads executing CPU-bound tasks will eventually show progress, even if none of them explicitly yields.
Nothing in the design of virtual threads prohibits using a preemptive scheduler as well. However, the default work-stealing scheduler is non-preemptive and non-cooperative (because the Project Loom team had not found any real scenarios in which it could be useful). So now virtual threads can only be suspended if they are blocked on I/O or another supported operation from the Java standard library. If you start a virtual thread with a CPU-bound task, that thread monopolizes the carrier thread until the task is completed, and other virtual threads may experience starvation.
*see “Modern Operating Systems”, 4th edition by Andrew S. Tanenbaum and Herbert Bos, 2015.
Write blocking synchronous code in the thread-per-request model
Blocking platform threads is expensive because it wastes limited computing resources. To fully utilize all computational resources, it is necessary to abandon the thread-per-request model. Typically, the asynchronous pipeline model is used instead, where tasks at different stages are executed on different threads. As an advantage, such asynchronous solutions reuse threads without blocking them, which allows programmers to write more scalable concurrent applications.
As a drawback, such applications are much more difficult to develop. The entire Java platform is designed on using threads as units of concurrency. In the Java programming language, control flow (branches, cycles, method calls, try/catch/finally) is executed in a thread. Exception has a stack trace that shows where in a thread the error occurred. The Java tools (debuggers, profilers) use thread as the execution context. Programmers lose all those advantages when they switch from the thread-per-request model to an asynchronous model.
In contrast, blocking virtual threads is cheap and moreover, it is their main design feature. While a blocked virtual thread is waiting for an operation to complete, the carrier thread and underlying OS thread are actually not blocked (in most cases). This allows programmers to write both simple and scalable concurrent applications in the thread-per-request model, which is the only style that is harmonious with the Java platform.
Do not pool virtual threads
Creating a platform thread is a rather long process because it requires the creation of an OS thread. Thread pools were designed to reduce this time by reusing threads between the execution of multiple tasks. They contain a pool of worker threads to which Runnable and Callable tasks are submitted through a queue.
Unlike creating platform threads, creating virtual threads is a fast process. Therefore, there is no need to create a virtual thread pool. You should create a new virtual thread for each task, even something as small as a network call. If the application requires an ExecutorService instance, you should use a specially designed implementation for virtual threads, which is returned from the Executors.newVirtualThreadPerTaskExecutor() static factory method. This executor does not use a thread pool and creates a new virtual thread for each submitted task. Also, this executor itself is lightweight, so you can create and close it at any code within the try-with-resources block.
Use semaphores instead of fixed thread pools to limit concurrency
The main purpose of thread pools is to reuse threads between the execution of multiple tasks. When a task is submitted to a thread pool, it is inserted into a queue. The task is retrieved from the queue by a worker thread for execution. An additional purpose of using thread pools with a fixed number of worker threads may be to limit the concurrency of a particular operation. Such thread pools can be used when an external resource cannot process more than a predefined number of concurrent requests.
However, since there is no need to reuse virtual threads, there is no need to use any thread pools for them. Instead, you should use a Semaphore with the same number of permits to limit concurrency. Just as a thread pool contains a queue of tasks, a semaphore contains a queue of threads blocked on its synchronizer.
Use thread-local variables carefully or switch to scoped values
To achieve better scalability of virtual threads, you should reconsider using thread-local variables and inheritable-thread-local variables. Thread-local variables provide each thread with its own copy of a variable, and inheritable-thread-local variables additionally copy these variables from the parent thread to the child thread. Thread-local variables are typically used to cache mutable objects that are expensive to create. They are also used to implicitly pass thread-bound parameters and return values through a sequence of intermediate methods.
Virtual threads support thread-local behavior (after much consideration by the Project Loom team) in the same way as platform threads. But since virtual threads can be much more numerous, the following features of thread-local variables can have a larger negative effect:
- unconstrained mutability (any code that can call the get method of a thread-local variable can call the set method of that variable, even if an object in a thread-local variable is immutable)
- unbounded lifetime (once a copy of a thread-local variable is set via the set method, the value is retained for the lifetime of the thread, or until code in the thread calls the remove method)
- expensive inheritance (each child thread copies, not reuses, inheritable-thread-local variables of the parent thread)
Sometimes, scoped values may be a better alternative to thread-local variables. Unlike a thread-local variable, a scoped value is written once, is available only for a bounded context, and is inherited in a structured concurrency scope.
Use synchronized blocks and methods carefully or switch to reentrant locks
To improve scalability using virtual threads, you should revise synchronized blocks and methods to avoid frequent and long-running pinning (such as I/O operations). Pinning is not a problem if such operations are short-lived (such as in-memory operations) or infrequent. Alternatively, you can replace a synchronized block or method with a ReentrantLock, that also guarantees mutually exclusive access.
Running an application with system property -Djdk.tracePinnedThreads=full prints a complete stack trace when a thread blocks while pinned (highlighting native frames and frames holding monitors), running with system property -Djdk.tracePinnedThreads=short prints just the problematic stack frames.
Conclusion
Virtual threads are designed for developing high-throughput concurrent applications when a programmer can create millions of units of concurrency with the well-known Thread class. Virtual threads are intended to replace platform threads in those applications with I/O-intensive operations.
Implementing virtual threads as a subclass of the existing Thread class was a trade-off. As an advantage, most existing concurrent code can use virtual threads with minimal changes. As a drawback, some Java concurrency constructs are not beneficial for virtual threads. Now it is the responsibility of programmers to use virtual threads correctly. This mainly concerns thread pools, thread-local variables, and synchronized blocks/methods. Instead of thread pools, you should create a new virtual thread for each task. You should use thread-local variables with caution and, if possible, replace them with scoped values. You should revisit synchronized to avoid pinning in long and frequently used methods of your applications. Finally, third-party libraries that you use in applications should be refactored by their owners to become compatible with virtual threads.
Complete code examples are available in the GitHub repository.